
Data Mining là gì? Các công cụ khai phá dữ liệu phổ biến nhất hiện nay
Data Science và Data Mining là hai trong số các lĩnh vực quan trọng nhất trong công nghệ. Cả hai lĩnh vực này đều xoay quanh dữ liệu.
Tuy nhiên, chúng sử dụng dữ liệu theo 2 cách khác nhau. Hơn nữa, kiến thức cần thiết để làm việc trong cả 2 lĩnh vực này cũng khác nhau. Bài viết dưới đây cung cấp kiến thức tổng quan về Data Mining.
Nội dung
Data Mining là gì?
Data mining – khai phá dữ liệu là quá trình phân loại, sắp xếp các tập hợp dữ liệu lớn để xác định các mẫu và thiết lập các mối liên hệ nhằm giải quyết các vấn đề nhờ phân tích dữ liệu. Các MCU khai phá dữ liệu cho phép các doanh nghiệp có thể dự đoán được xu hướng tương lai.
Quá trình khai phá dữ liệu là một quá trình phức tạp bao gồm kho dữ liệu chuyên sâu cũng như các công nghệ tính toán. Hơn nữa, Data Mining không chỉ giới hạn trong việc trích xuất dữ liệu mà còn được sử dụng để chuyển đổi, làm sạch, tích hợp dữ liệu và phân tích mẫu.
Có nhiều tham số quan trọng khác nhau trong Data Mining, chẳng hạn như quy tắc kết hợp, phân loại, phân cụm và dự báo. Một số tính năng chính của Data Mining:
- Dự đoán các mẫu dựa trên xu hướng trong dữ liệu.
- Tính toán dự đoán kết quả
- Tạo thông tin phản hồi để phân tích
- Tập trung vào cơ sở dữ liệu lớn hơn.
- Phân cụm dữ liệu trực quan
Xem thêm: Data Science là gì? Vai trò của một Data Scientist
Các bước trong Data Mining
Các bước quan trọng khi Data Mining bao gồm:
Bước 1: Làm sạch dữ liệu – Trong bước này, dữ liệu được làm sạch sao cho không có tạp âm hay bất thường trong dữ liệu.
Bước 2: Tích hợp dữ liệu – Trong quá trình tích hợp dữ liệu, nhiều nguồn dữ liệu sẽ kết hợp lại thành một.
Bước 3: Lựa chọn dữ liệu – Trong bước này, dữ liệu được trích xuất từ cơ sở dữ liệu.
Bước 4: Chuyển đổi dữ liệu – Trong bước này, dữ liệu sẽ được chuyển đổi để thực hiện phân tích tóm tắt cũng như các hoạt động tổng hợp.
Bước 5: Khai phá dữ liệu – Trong bước này, chúng tôi trích xuất dữ liệu hữu ích từ nhóm dữ liệu hiện có.
Bước 6: Đánh giá mẫu – Chúng tôi phân tích một số mẫu có trong dữ liệu.
Bước 7: Trình bày thông tin – Trong bước cuối cùng, thông tin sẽ được thể hiện dưới dạng cây, bảng, biểu đồ và ma trận.
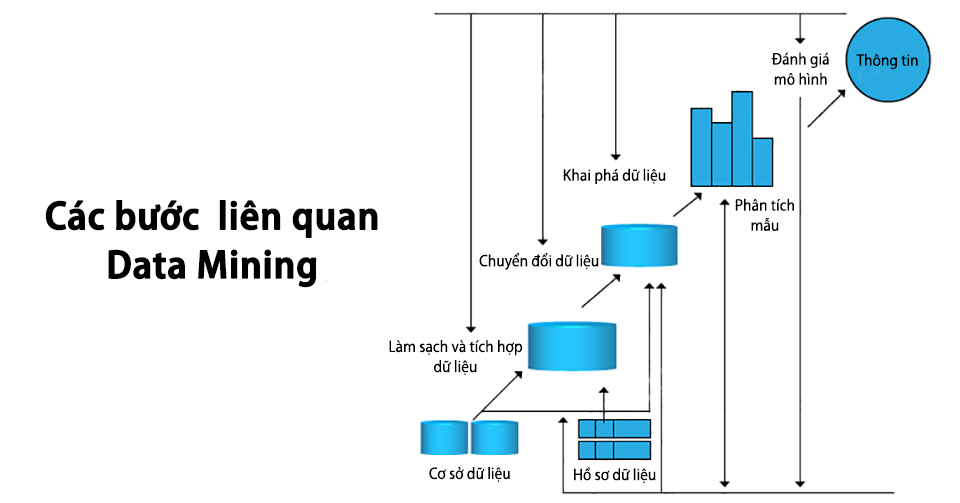
Các bước trong Data Mining
Ứng dụng của Data Mining
Có nhiều ứng dụng của Data Mining thường thấy như:
- Phân tích thị trường và chứng khoán
- Phát hiện gian lận
- Quản lý rủi ro và phân tích doanh nghiệp
- Phân tích giá trị trọn đời của khách hàng
- Khám phá thêm 10 ứng dụng khai phá dữ liệu
Các công cụ khai phá dữ liệu
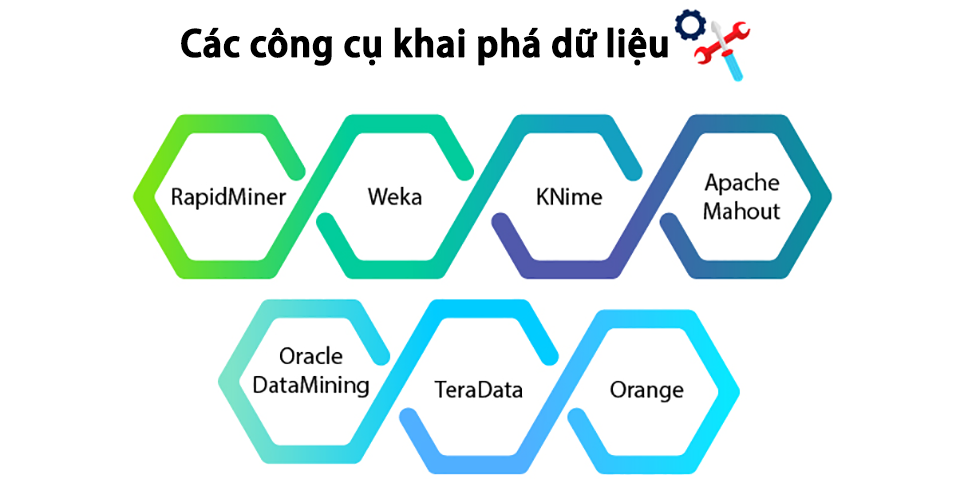
Các công cụ khai phá dữ liệu
- RapidMiner
Là một trong những công cụ phổ biến nhất để khai phá dữ liệu, RapidMiner được viết trên nền tảng Java nhưng không yêu cầu mã hóa để vận hành. Hơn nữa, nó cung cấp các chức năng khai thác dữ liệu khác nhau như tiền xử lý dữ liệu, biểu diễn dữ liệu, lọc, phân cụm, v.v.
- Weka
Weka là một phần mềm khai thác dữ liệu mã nguồn mở được phát triển tại Đại học Wichita. Giống như RapidMiner, Weka không có mã hóa và sử dụng GUI đơn giản.
Sử dụng Weka, bạn có thể gọi trực tiếp các thuật toán học máy hoặc nhập chúng bằng mã Java. Nó cung cấp một loạt các công cụ như trực quan hóa, tiền xử lý, phân loại, phân cụm, v.v.
- KNime
KNime là một bộ khai phá dữ liệu mạnh mẽ, chủ yếu được sử dụng cho tiền xử lý dữ liệu, đó là, ETL: Trích xuất, Chuyển đổi & Tải. Hơn nữa, nó tích hợp nhiều thành phần khác nhau của khoa học máy và khai phá dữ liệu để cung cấp một nền tảng bao gồm cho tất cả các hoạt động phù hợp.
- Apache Mahout
Apache Mahout là một phần mở rộng của Nền tảng Big Data Hadoop. Các nhà phát triển tại Apache đã phát triển Mahout để giải quyết nhu cầu ngày càng tăng về khai phá dữ liệu và hoạt động phân tích trong Hadoop.
Kết quả là, nó chứa các chức năng học máy khác nhau như phân loại, hồi quy, phân cụm, v.v.
- Oracle DataMining
Oracle DataMining là một công cụ tuyệt vời để phân loại, phân tích và dự đoán dữ liệu. Nó cho phép người dùng thực hiện khai phá dữ liệu trên cơ sở dữ liệu SQL để trích xuất các khung hình và biểu đồ.
- TeraData
Đối với dữ liệu, nhập kho là một yêu cầu cần thiết. TeraData, còn được gọi là Cơ sở dữ liệu TeraData cung cấp dịch vụ kho chứa các công cụ khai phá dữ liệu.
Nó có thể lưu trữ dữ liệu dựa trên mức độ sử dụng của chúng, nghĩa là, nó lưu trữ dữ liệu ít được sử dụng trong phần ‘slow’ và cho phép truy cập nhanh vào dữ liệu được sử dụng thường xuyên.
- Orange
Phần mềm Orange được biết đến bởi việc tích hợp các công cụ khai phá dữ liệu và học máy. Nó được viết bằng Python và cung cấp trực quan tương tác và thẩm mỹ cho người dùng.
Xem thêm: Top 6 ngôn ngữ lập trình khoa học dữ liệu thường gặp
Nguồn: data-flair.training


